*本文原创作者:grt1stnull,本文属FreeBuf原创奖励计划,未经许可禁止转载
感谢hanc00l爬取了wooyun的网页,才使乌云关闭后,大家依旧可以访问以前的漏洞库、知识库。hanc00l发布了基于flask或者torndo的乌云公开漏洞、知识库搜索的github项目,同时发布了已经配置好的虚拟机,允许大家直接把乌云搭建在了本地。
为了方便的在本地进行乌云搜索,我准备把乌云搜索搭建在树莓派上。但是,hanc00l使用的数据库是mangodb,总数据在6GB左右。32位的mangodb支持的总共数据大小最大是2GB,而我的树莓派正是32位,所以我没办法在树莓派上布置。于是利用静态的乌云漏洞库、知识库,我自己建立了数据库、搜索页面,实现了可在apache、nginx等上布置,基于mysql数据库的乌云知识库、漏洞库搜索项目。
我的项目使用python依次处理静态页面,用正则抽取出信息再批量插入数据库;之后又写了个php,实现了对数据库的搜索。
二.python的经验分享
我在python中利用的扩展库是BeautifulSoup与MySQLdb。关于这两个库的介绍有很多,下面我主要介绍下我对这两个库的操作。
1)beautifulsoup的使用
from bs4 import BeautifulSoup #引用库 soup=BeautifulSoup(html,"html.parser") #创建BeautifulSoup对象,html为目标
corps=soup.find_all('p',class_='words') #从对象中查找类名为words的p的标签
大家可以输出一下试试
2)MySQLdb的使用
import MySQLdb #引用库 try: #错误处理
conn=MySQLdb.connect(host='localhost',port=3306,user='root',passwd='',db='wooyun',charset='utf8') #建立连接,host主机、port端口(默认3306)、user用户、passwd密码、db操作的库、charset字符编码
cur=conn.cursor() #获取操作游标
reload(sys)
sys.setdefaultencoding('utf-8') #设置编码
tmp=(title1,date1,author1[0],type1[0],corp1[0],docs) #要插入的数组
cur.execute("INSERT INTO `bugs`(`title`,`dates`,`author`,`type`,`corp`,`doc`) VALUES(%s,%s,%s,%s,%s,%s)",tmp) #插入数据库
conn.commit() #提交操作,插入时不可省
cur.close()
conn.close() #关闭连接,释放资源
except MySQLdb.Error,e:
print "Mysql Error %d: %s" % (e.args[0], e.args[1]) #如果出错,输出错误
对于mysql不是很熟悉的同学如果有phpmyadmin的话可以在phpmyadmin中操作一下数据库,可以预览mysql语句。也可以在mysql命令行中执行语句尝试。
三.php的经验分享
虽然以前一直会php和css,但是这是第一次真正写一个动态页面。
首先对参数进行过滤。判断是否为整数数字:
if(is_numeric($_GET['page'])&&is_int($_GET['page']+0)){
#code
}
php中标签的输出是这样的!
echo "<p style=\"display:inline-block;\">haha</p>";bootstrap很好用!
推荐链接:
php对数据库的处理:
现在版本的php不再推荐MYSQL函数了,建议使用PDO或者mysqli
本来想使用pdo的,想感受一下预处理。但是pdo会对参数中的某些字符进行转义。无论我怎么处理都会报错,最终我决定使用mysqli了。
//mysql建立连接
$db=new mysqli('localhost','root','','wooyun'); //localhost:3307
//sql对象错误检查
if(mysqli_connect_errno()){
echo '<br>Error:Please try again later.';
exit(); }
参数如上,不解释了。host有两种方式,默认端口是localhost;指定端口是localhost:3307
$query0="SELECT count(*) FROM `".$kind."` WHERE `title` LIKE '%".$keywords."%'"; #mysql语句
$num=$db->query($query0); #执行该语句
$row=$num->fetch_row(); #取得结果
四.后记
在课业之余用了10天时间搭建完成,见识了很多扩展,很有帮助。
我的新浪微博:http://weibo.com/grt1st
项目github地址:https://github.com/grt1st/wooyun_search
*本文原创作者:grt1stnull,本文属FreeBuf原创奖励计划,未经许可禁止转载
-
 可惜了,乌云关闭的锅我觉得该PR背,早在zf那边打点好,把利益拴在一起,根本就没这事了
可惜了,乌云关闭的锅我觉得该PR背,早在zf那边打点好,把利益拴在一起,根本就没这事了 -
 圈内人xx出不来了,总是吹牛逼关系多硬,然而最后没有什么卵用。 跟他一起的哥们更惨,目测七年以上
圈内人xx出不来了,总是吹牛逼关系多硬,然而最后没有什么卵用。 跟他一起的哥们更惨,目测七年以上 -
 武汉市国家安全局@ CNZ 这就是夜壶的故事,用的时候需要,不用的时候嫌脏。所以说说翻脸就翻脸太正常了
武汉市国家安全局@ CNZ 这就是夜壶的故事,用的时候需要,不用的时候嫌脏。所以说说翻脸就翻脸太正常了 -
 dean乌云知识库 PC版本:http://www.php0.net Android版本:http://android.myapp.com/myapp/detail.htm?apkName=net.php0.blackbook
dean乌云知识库 PC版本:http://www.php0.net Android版本:http://android.myapp.com/myapp/detail.htm?apkName=net.php0.blackbook -
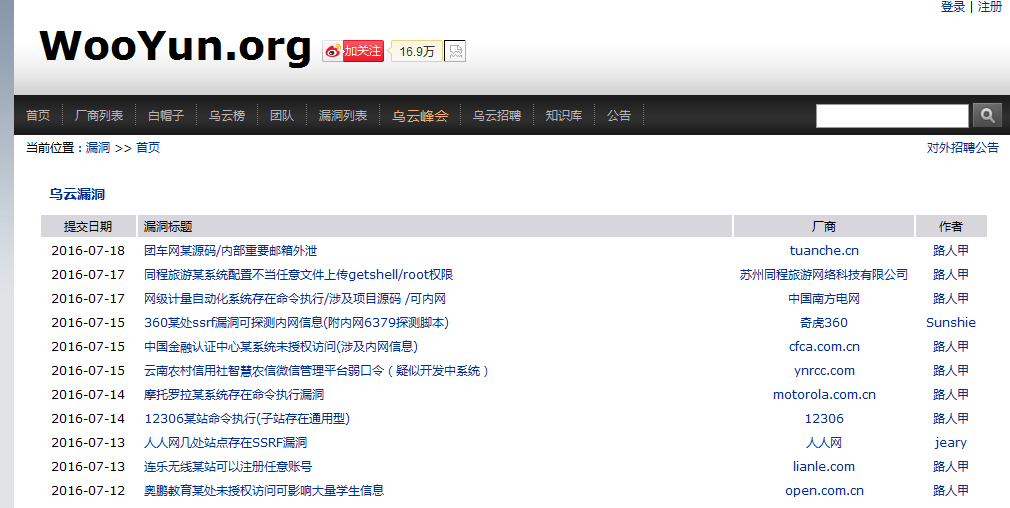
 乌云我还是喜欢这样的
乌云我还是喜欢这样的


 关注我们 分享每日精选文章
关注我们 分享每日精选文章




Copyright © 2013 WWW.FREEBUF.COM All Rights Reserved 沪ICP备13033796号
![]()
0day

已有 40 条评论
点个赞
@ FireTao wy.loner.fm
能搞个docker版的不
可惜了,乌云关闭的锅我觉得该PR背,早在zf那边打点好,把利益拴在一起,根本就没这事了
@ CNZ 这就是夜壶的故事,用的时候需要,不用的时候嫌脏。所以说说翻脸就翻脸太正常了
其实我是来看mysqldb的断线重连的
@ DragonEgg 我是每次写入前再建立连接,所以没断线过。你倒是提醒我了可以在开始处建立连接,添加中途断线处理,如果这样效率更高我会考虑这种方法的。
@ grt1stnull 可以用ping()自己判断
import MySQLdb
def connect():
conn = MySQLdb.connect(user="root",passwd="12345",host="localhost",db="test")
return conn
c = connect()
def xxx():
global c
try:
c.ping()
except:
c = connect()
@ DragonEgg 好的,感谢
不错不错,吧drop搭起来!
我还是喜欢这样的


@ 乌云 我也是,唉
@ grt1stnull wy.loner.fm
我就是通过这条微博找到你的…23333
听上去不错
https://github.com/CaledoniaProject/wooyun_offline_ui … 楼主累不累
@ 123 如果你看了我的项目就会发现这和我的完全不一样
@ grt1stnull 你的服务项目不错,比起员作者的搭建起来容易很多,,请问下wooyun数据库文件全部解压分别放到bugs、drops两个文件夹就行了吗
@ 夜尽天明 是的
感谢关注[doge]
很早就有人把乌云爬下来并存档放在互联网
乌云知识库 PC版本:http://www.php0.net Android版本:http://android.myapp.com/myapp/detail.htm?apkName=net.php0.blackbook
xx出不来了,总是吹牛逼关系多硬,然而最后没有什么卵用。
跟他一起的哥们更惨,目测七年以上
@ 圈内人 能不装逼呢?你懂个屁? 7年?你知道什么罪么?
@ 某云 你知道个屁
@ 周鸿伟 你们naive,人都放出来了,还7年,不过现在还在取保,不敢吱声而已.
不错不错
换马甲
厉害了,我的哥
mangodb 是什么,看到这就没兴趣了。
我要wiki.wooyun.org
神奇的作者, 我这有wiki的数据,请多多指教下怎么写呢
我就问问 那个有最新的wooyun知识库.
编码有问题,为啥?
@ x1aog 先把服务器设置支持中文utf-8的编码。你这种情况是汉字乱码
怎么改
乌云知识库,漏洞查询网址http://wooyun.tangscan.cn
200M带宽,查询杠杆的
前几天刚在石家庄这边碰到hancool本人 zz….
我早就倒入到了wp里,drops.the404.me
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
import os
import time
from bs4 import BeautifulSoup
from wordpress_xmlrpc import Client, WordPressPost
from wordpress_xmlrpc.methods.posts import NewPost
reload(sys)
sys.setdefaultencoding(‘utf-8′)
dir=’/Users/the404/drops’
def readfile():
listfile = os.listdir(dir)
for name in listfile:
filepath = dir + ‘/’+name
print filepath
soup = BeautifulSoup(open(filepath),"html.parser")
title = soup.find(‘title’).string
title = str(title)
body = soup.body
h1 = body.find_all(‘h1′)
del_h1 = h1[0].extract() #删除文章第一个h1的来源
refer = "原文链接:%s"%h1[0].a
content = str(body)+refer
#print content
#print title
try:
sends(title,content)
os.system(‘mv \’%s\’ /Users/the404/ok/’%filepath)
except:
print "error"
os.system(‘mv \’%s\’ /Users/the404/error/’%filepath)
#time.sleep(2)
def sends(title,html):
wp = Client(‘http://172.16.208.100/wordpress/xmlrpc.php’,'drops’,'password’)
post =WordPressPost()
post.title = title
post.content = html
post.post_status = ‘publish’
post.terms_names = {
‘category’ : ['drops']#分类目录
}
wp.call(NewPost(post))
#print content
if __name__==’__main__’:
readfile()
”’
soup = BeautifulSoup(html,"html.parser")
# print soup.prettify()
title = soup.find(‘title’)
title = title.string
body = soup.body #获取body内的信息
# tag = soup.h1[0]
#tag = tag.extract()
#print soup
h1 = body.find_all(‘h1′)
del_h1 = h1[0].extract() #删除文章第一个h1的来源
refer = h1[0].a
print body
refer = "原文链接:%s"%refer
print refer
# print h1
# x = h1[1].extract()
# print soup
# print x
”’
wy.loner.fm